

The Economic Case for Edge Infrastructure
Edge computing shifts processing away from centralized cloud data centers and closer to where the user actually is. On paper, that sounds like a technical detail, but in practice it changes how cost, speed, and reliability show up in day to day operations. Most cloud systems process every action remotely, which means every transaction, request, or update depends on a constant back and forth with external infrastructure. A point of sale system is a simple example, every transaction travels out, gets processed, and comes back, and that loop repeats all day.
With an edge setup, a large part of that loop disappears. Transactions are handled locally, and only the data that actually needs to be shared is pushed to the cloud. At a small scale, this difference is easy to miss, but once volume increases or multiple locations come into play, the shift becomes noticeable. Costs stop scaling in the same way, and performance becomes more predictable. This also connects to a broader idea discussed in The Real Cost of Not Owning Your Customer Data, where dependency on external systems quietly compounds risk and cost over time.
(An infographic showing Internet of Things components including cloud computing, big data, edge computing, and connected sensors)
Latency Reduction and Real Time Application Performance
Latency is often treated as a technical metric, but it’s really just distance translated into time. The further your system is from the user, the longer everything takes. A request from rural Tamil Nadu to a server in Mumbai might take anywhere between 40 and 120 milliseconds depending on network conditions, and while that delay feels small in isolation, it rarely happens just once. Systems rely on continuous interaction, so those milliseconds stack up.
When processing moves closer to the user, those delays shrink significantly. In some cases, responses happen in under 5 milliseconds, which changes how systems feel to use. Video calls are the most obvious example, because once latency gets high enough, conversations stop feeling natural. Audio overlaps, responses lag, and the experience breaks down. The same pattern shows up in inventory systems, where small delays per action multiply across thousands of interactions. This is closely related to the idea in Why Speed of Understanding Matters More Than Speed of Loading, where perceived responsiveness ends up mattering more than raw performance numbers.
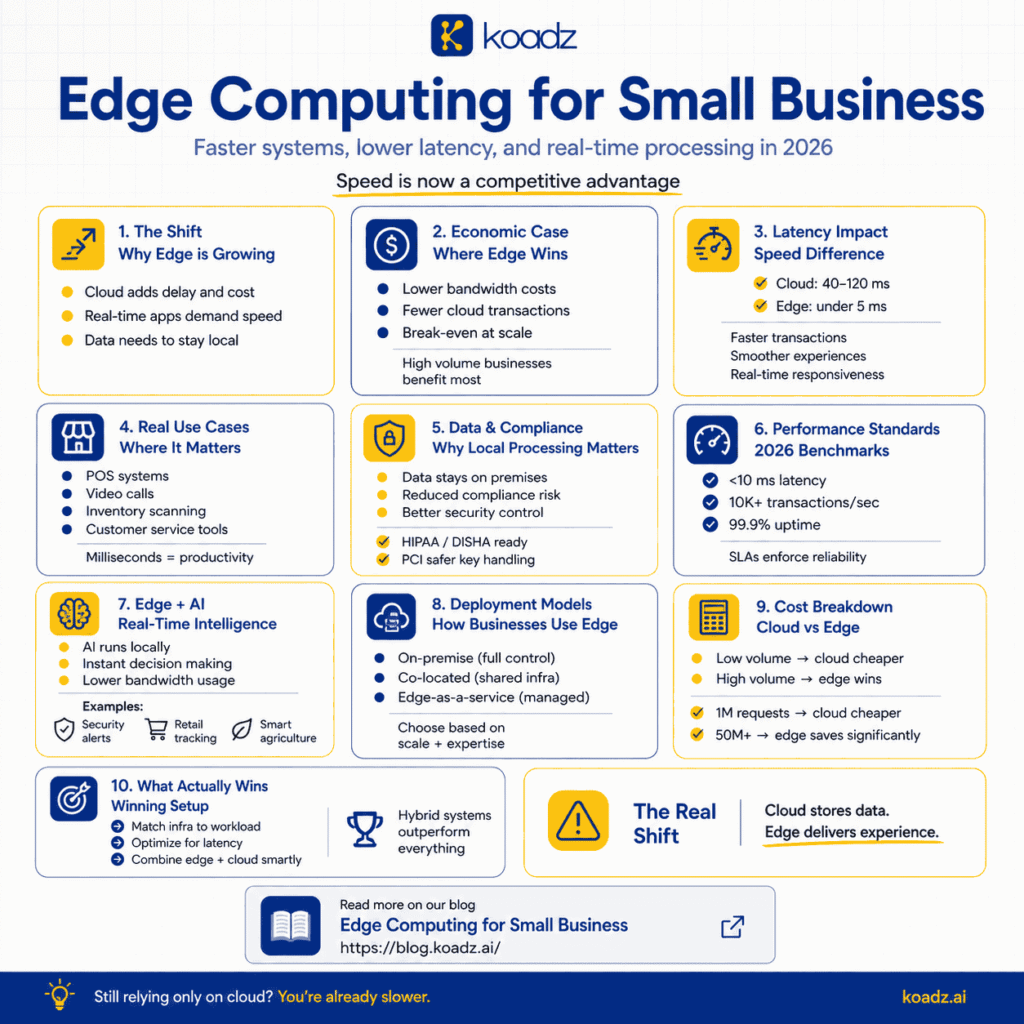
(An infographic summarizing how edge computing improves speed, reduces latency, and enables local data processing for small businesses)
Local Data Processing and Regulatory Compliance
Regulation adds another layer that often gets overlooked until it becomes a problem. In regions like India or the European Union, certain types of data are required to stay within national boundaries. Cloud providers try to manage this through regional infrastructure, but failover systems can still route data in ways that create compliance risk.
Edge computing avoids that situation by default because data stays local unless explicitly moved. A healthcare clinic handling patient records, for instance, cannot afford unnecessary exposure. Keeping that data on premises, encrypting it locally, and only sharing what is required reduces dependency on external systems. The same applies to financial systems, where payment data needs to remain secure at every stage. This links back to The Real Cost of Not Owning Your Customer Data, where control over data directly affects both risk and long term stability.

(A cloud network visualization showing connected data systems, representing cloud infrastructure and data flow in modern computing)
Performance Benchmarks and Service Level Agreements
By 2026, expectations around edge performance have become more defined, but they are still tied closely to use case rather than fixed numbers. Most systems aim for low latency, consistent uptime, and enough throughput to handle peak demand without failure. Service level agreements formalize these expectations, typically guaranteeing uptime around 99.9 percent and outlining penalties when those thresholds are not met.
What matters more than the numbers themselves is how well the infrastructure matches the actual workload. A system designed for content delivery behaves very differently from one running machine learning models, and treating them the same leads to inefficiencies. Monitoring plays a quiet but important role here, because without visibility into real time performance, small issues can go unnoticed until they become larger operational problems.
Edge Resident AI and Autonomous Decision Making
One of the more meaningful shifts with edge computing is that AI no longer needs to rely entirely on the cloud. Instead of sending data out for processing and waiting for a response, decisions can be made at the source itself. A security camera, for example, can analyze footage locally and trigger alerts only when something unusual happens, instead of streaming everything continuously.
This reduces bandwidth usage, lowers processing cost, and improves response time all at once. Retail systems apply the same idea by analyzing customer behavior in real time and adjusting layouts or promotions without needing centralized processing. In environments like agriculture, where connectivity is unreliable, this becomes even more important because systems need to operate independently. It also ties into How to Measure Experience, Not Just Performance, since the value here is not just speed, but how the system behaves under real conditions.
Vendor Landscape and Deployment Models
There isn’t a single way to approach edge computing, and most businesses end up choosing based on their constraints rather than ideal scenarios. Some go with on premises setups, which offer full control but also require the ability to manage hardware and systems internally. Others use nearby data centers, which reduce operational effort while still keeping processing close enough to maintain low latency.
Then there are managed models where vendors handle deployment, updates, and monitoring, making it easier for smaller teams to adopt without heavy upfront investment. The choice usually depends on how much control is needed, how complex the system is, and how costs are expected to evolve over time rather than just the initial setup.

(A cloud-based network illustration showing connected servers and data systems, representing scalable computing infrastructure and data processing)
Cost Analysis and Return on Investment
Cost is where the tradeoffs become more visible. At lower volumes, cloud systems tend to be more economical because they scale gradually and do not require upfront investment. However, as usage grows, costs increase in proportion to demand, while edge systems remain relatively stable once infrastructure is in place.
This creates a tipping point where edge computing becomes more cost effective, especially at higher volumes. Beyond direct cost comparisons, there are also indirect effects that are harder to quantify but still important. Lower latency improves user experience, local processing reduces compliance risk, and reduced dependency on centralized systems improves resilience. These factors often matter more over time than the initial cost difference, especially for businesses where performance and reliability directly influence customer outcomes.